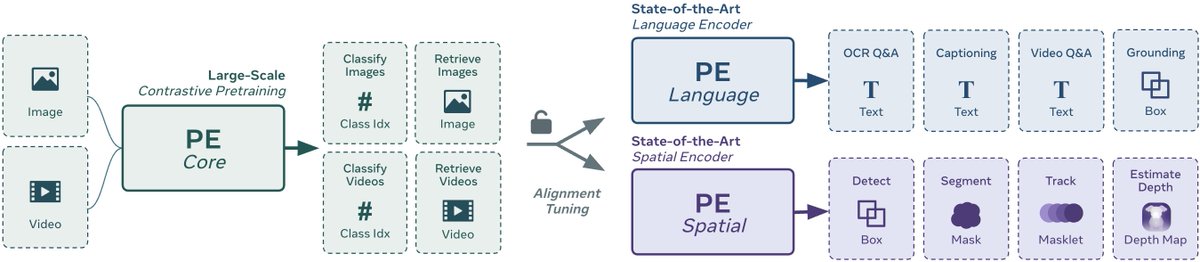
شامل دو سری مدل میشه :
۱- مدلهای Perception Encoder (PE) برای encode کردن عکس و ویدیو.
این خانواده از مدلها سه نسخه تخصصی داره:
– مدل PE core: مدلی به سبک CLIP برای طبقهبندی و بازیابی تصاویر/ویدیوها بهصورت zero shot.
-مدل PE lang: هماهنگسازی vision encoders ها با مدلهای زبانی بزرگ برای عملکرد قوی در وظایف چندرسانهای.
– مدل PE spatial: مناسب برای وظایف پیشبینی متراکم مانند تشخیص، تخمین عمق و ردیابی.
این مدلها از مدلهای پیشرفتهای مانند SigLIP2، InternVideo2، QwenVL2.5 و DINOv2 پیشی گرفتهاند.
۲- مدلهای Perception Language Model (PLM). یک مدل زبانی چندرسانهای برای درک دقیقتر تصاویر و ویدیوها:
– ترکیب یک vision encoder با یک دیکودر مدل زبانی با کمتر از ۸ میلیارد پارامتر.
پرسشپاسخ ویدیو و کپشنهای مرتبط با فضا و زمان.
– معرفی PLM–VideoBench برای ارزیابی درک ویدیو
این مدلهای جدید برای پیاده سازی انواع اپلیکیشن هایی که با تصویر و ویدیو هست کاربرد داره